Introduction to kernel
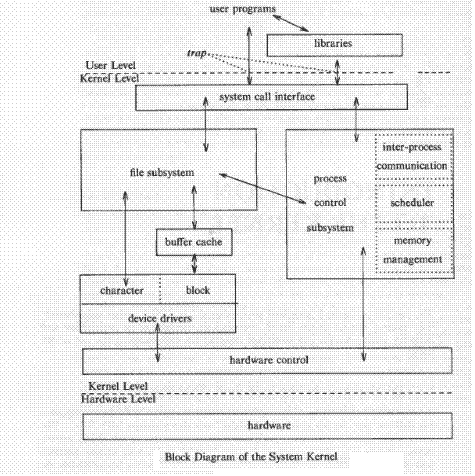
Introduction to system concepts – overview of file subsystem
The internal representation of the file is in the form of iNode. This inode contains the information about the file such as its layout on the disk, its owner, its access permissions and last accessed time.
This inode is short form for index node. Every file has one inode. The inodes of all the files on the system are stored in inode table. When we create a new file a new entry in the inode table is created.
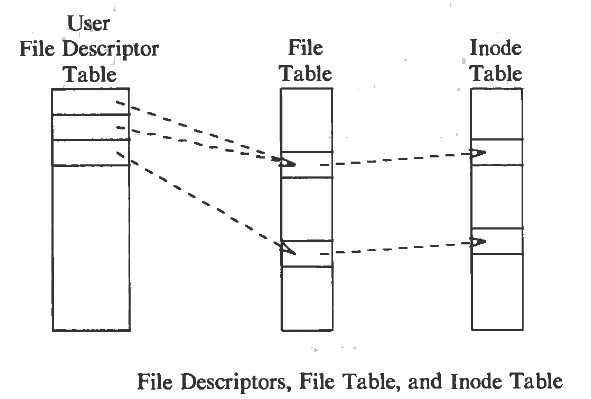
The kernel contain two data structures file table and user file descriptor table. The file table is global table at the kernel level but the user file descriptor table s for every process. When a process creates a file or opens a file the entry for that is made in both the tables.
The information about the current state of the file is maintained in the file table. For example if the file is being written the information about the current cursor position is kept in the file table. This file table also checks whether the accessing process has access to that file or not.
The user file descriptor table keeps a track of all the files opened by the processes and what are the relationships between these files.
The regular files and folders are kept on block devices like disks and tape drives. The drive has logical block numbers and physical block numbers and the mapping from logical to physical block numbers is done by disk driver.
File system layout

- The boot block occupies the beginning of the file system. This contains the bootstrap code that is required for the machine to boot.
- Super block describes the state of the file system i.e. its size, maximum number of files that can be stored and the free space information.
- The inode list contains the inode table and the kernel references the inode list area to get the information about the files stored on the machine.
- The data block is the end of the inode list and starting of the blocks that can be used to store the user files. The starting area of the data block will contain some administrative files and information and the later block contains the actual files.
Introduction to system concepts – Process subsystem
A process on unix can be created by executing the fork system call. Only the process 0 is created without using this system call and all other processes are created using the fork system call. (Process 0 was created manually by booting the system.)
The process that executes fork is called the parent process and the process that was created is called the child processes. A process can have many child but only one parent.
Kernel identifies every process by a unique identifier called the process ID or PID.
Process regions:
Text : The information about the instructions of the process
Data: The uninitialized data members (buffer)
Stack: logical stack frames created during function calls. This is created automatically and grows dynamically.
Since the processes in unix executes in two modes, kernel and user. There are separate stacks for both the modes.
All the processes in the system are identified by PID which are stored in the process table. Every process has an entry in the kernel process table. Every process is allocated the u-area(user area in the main memory. The region is the contiguous area of process addresses.
The processes table entry and u area controls the status information about the process. U area is extension of process table entry.
Context of a process
Context of a process is state. When a process is executing the process has a context of execution. When the process shifts from the running to waiting state the context switching takes place.
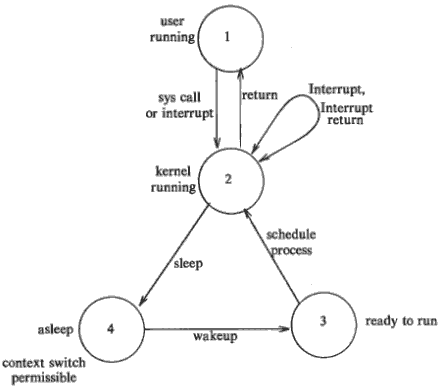
Process states
Process state in unix could be one of the following
- Ready
- Running in user mode
- Running in kernel mode
- Sleeping/waiting
- Terminated
State transition
Kernel data structures
The kernel data structures occupy fix size tables rather than dynamically allocated space. This approach has one advantage, the kernel code is simpler but there is one disadvantage of this approach too. It limits the number of entries in these data structures.
So if there are free entries in the kernel data structures we are wasting the potential resources of kernel and if, on the other hand the kernel data structure table is free we need to find a way to notify the processes that something has gone wrong.
The simplicity of kernel code, which is because of this limited size of data structures has far too many advantages than disadvantages.
System Administration
Processes that do various functions performed for the general welfare of the user community. Conceptually there is no difference between administrative process and user process. They use same set of system calls user processes do.
They only differ from user processes in rights and privileges they have. So to summarize, kernel cannot distinguish between kernel process and user process it is just the permission of processes and files that some behave as administrative processes and some behave as the user processes.